
革命性的文档理解视觉文本压缩技术
开源模型,在 10 倍压缩比下达到 97% 准确率。单 GPU 每天处理 20 万页文档。支持 100+ 语言。MIT 许可证。
开源 | MIT 许可证 | 100+ 语言支持
免费在线体验 DeepSeek OCR
通过我们的免费在线演示体验 DeepSeek OCR。上传文档,实时体验革命性的视觉文本压缩技术。无需注册 - 立即开始使用我们的免费 OCR 工具。
🚀 DeepSeek OCR Free Online • No registration required • Process documents instantly with our free OCR tool
赞助商
Pollo AI 视频生成器
通过 Pollo AI 视频生成器,您可以使用我们的旗舰 Pollo 1.6 视频模型以及行业内所有顶级视频模型,如 Kling AI、Veo 3、Runway、Seedance、海螺 AI、Pika AI、PixVerse AI、度加 AI、Luma AI、万兴 AI 和混元等。
在 HIX AI 上与所有前沿模型对话
通过 HIX AI,您可以与所有先进模型对话,如 GPT-5、OpenAI o3、Claude Opus 4.1、Gemini 2.5 Pro、Grok 3、DeepSeek-R1/V3 等。我们持续更新驱动 HIX AI 的语言模型,让您率先体验最新的 AI 发展。
构建在先进的 AI 技术之上





什么是 DeepSeek OCR?
突破性的开源光学字符识别模型,引入上下文光学压缩技术,实现前所未有的效率。
- 10 倍压缩比在 10 倍压缩比下达到 97% 准确率。即使在 20 倍压缩下仍保持 60% 精度。
- 3.8 亿参数编码器DeepEncoder 架构结合 SAM-base(8000 万)、CLIP-large(3 亿)和 16 倍卷积压缩器,实现高效的视觉文本映射。
- 企业级性能单个 A100-40G GPU 每天处理 20 万页文档,DeepSeek3B-MoE 解码器具有 5.7 亿激活参数。
为什么选择 DeepSeek OCR 进行文档处理?
DeepSeek OCR 免费在线提供企业级 OCR 功能,相比传统解决方案具有明显优势。我们的免费 OCR 工具将尖端 AI 技术与实用的部署灵活性相结合。
卓越的成本效益
DeepSeek OCR 免费在线相比传统 OCR 解决方案降低 97% 的运营成本。在单个 GPU 上每日处理 20 万+页面,同时保持企业级准确性。我们的免费在线 OCR 工具消除了按页许可费和 API 成本。
无与伦比的性能
我们的 OCR 工具免费达到 97% 准确率和 10 倍压缩比,在标准化基准测试中优于 GPT-4o 和 GOT-OCR2.0。DeepSeek OCR 在线在 100+ 种语言中提供企业级可靠性的一致结果。
完整数据隐私
部署 DeepSeek OCR 本地化处理敏感文档。我们的免费 OCR 工具确保您的数据永不离开基础设施,满足 GDPR、HIPAA 和企业合规要求,同时不影响性能。
便捷集成
DeepSeek OCR 在线通过 HuggingFace、Docker 和 REST API 与现有工作流程无缝集成。我们的免费在线 OCR 解决方案提供全面的文档和示例实现,快速部署。
面向未来的技术
基于 SAM、CLIP 和 PyTorch 等成熟基础构建,DeepSeek OCR 免费代表了光学字符识别的最新进展。定期更新和 MIT 许可确保您的 OCR 工具需求的长期可行性。
专业支持
访问全面的文档、社区支持和专业级资源。我们的 OCR 工具免费提供详细教程、最佳实践和活跃的社区论坛,用于故障排除和优化。
由顶尖 AI 研究团队开发
DeepSeek OCR 免费在线由 DeepSeek-AI 开发,这是一个专门从事大型语言模型和计算机视觉的先驱研究组织。我们的团队结合顶尖大学和行业领导者的专业知识,提供尖端的 OCR 技术。
行业领先的性能指标
在综合基准测试和生产工作负载上得到验证
准确率
97%
10 倍压缩下
吞吐量
20万+
页/天
语言
100+
支持
标记效率
97%
vs MinerU2.0
DeepSeek OCR 核心功能
重新定义文档理解和文本提取的先进功能
上下文光学压缩
革命性技术,在保持 97% 准确率的同时将视觉信息压缩 10 倍。智能地保留关键特征而消除冗余,实现比传统系统更少标记的更快处理。
多分辨率模式
从 Tiny(64 标记)到 Gundam-M(1,853 标记)的六种分辨率模式。根据特定文档处理要求选择准确性和性能的最佳平衡。
卓越基准
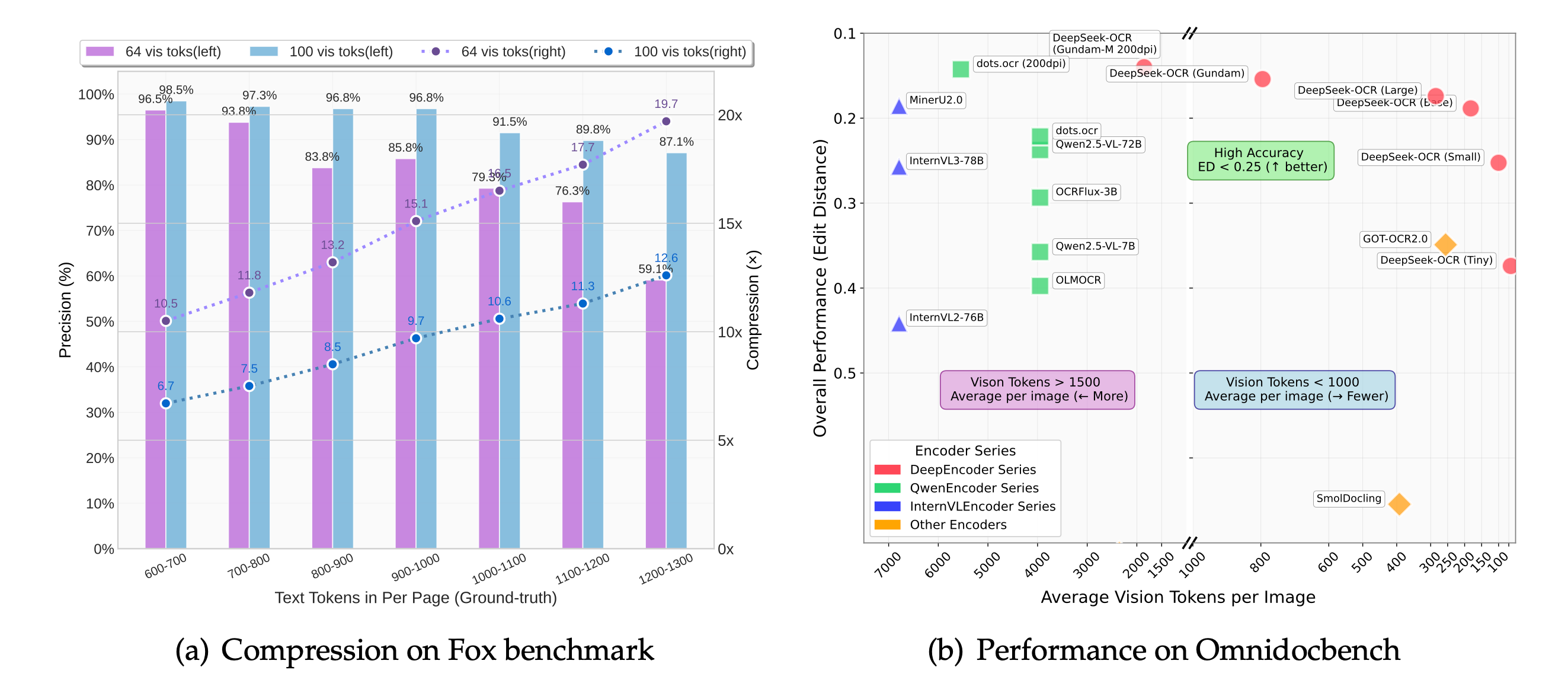
在 OmniDocBench 上超越 GPT-4o(0.137 vs 0.233 英文编辑距离)和 GOT-OCR2.0。使用比 MinerU2.0 少 97% 的标记实现相当准确性。
OCR 2.0 能力
超越文本提取:解析图表和图形,识别化学公式,理解几何图形,转换为 Markdown 格式时保留文档布局。
多语言支持
全面支持 100+ 语言,包括中文、日文、韩文、阿拉伯文、西里尔文和印度文字。所有语言边界上的一致准确性。
生产就绪
MIT 许可证商业使用。本地或云部署。全面的文档和 HuggingFace 集成,快速采用。
性能基准:效率与准确性的结合
OmniDocBench 上的综合评估证明了卓越的性能
实际应用场景
从企业文档管理到学术研究,DeepSeek OCR 支持各种用例

关于 DeepSeek OCR 的常见问题
了解更多关于 DeepSeek OCR 的能力和实现
DeepSeek OCR 如何用更少的标记实现比 GPT-4o 更好的准确性?
DeepSeek OCR 的上下文光学压缩技术智能地压缩视觉信息,同时保留文本提取的必要特征。DeepEncoder 架构结合了三个专用组件——用于视觉理解的 SAM-base、用于视觉-语言对齐的 CLIP-large 和 16 倍卷积压缩器。这种专门为 OCR 优化的架构相比通用多模态模型提供了优势,以 97% 的准确率保持实现 10 倍压缩。
我可以将 DeepSeek OCR 用于商业应用吗?
是的,DeepSeek OCR 以 MIT 许可证发布,允许自由使用、修改、分发和商业化,无需任何限制或版税支付。组织可以在本地部署 DeepSeek OCR 进行敏感文档处理,将其集成到商业产品中,或作为付费服务的一部分提供。生产就绪性能(单个 A100 GPU 每天 20 万页以上)使其成为寻求经济高效、合规的文档解析解决方案的企业的理想选择。
DeepSeek OCR 支持哪些语言?
DeepSeek OCR 支持 100 多种语言,包括拉丁文字(英语、西班牙语、法语、德语)、亚洲语言(中文、日文、韩文)、阿拉伯文字、西里尔文(俄语、乌克兰语)和印度语言(印地语、孟加拉语、泰米尔语等)。多语言能力内置于核心架构中,确保跨语言的一致准确性。
DeepSeek OCR 在效率方面与 MinerU2.0 相比如何?
DeepSeek OCR 在保持相当准确性的同时展示了相对于 MinerU2.0 的显著效率优势。MinerU2.0 需要 6,790 个视觉标记来实现 0.133 英文和 0.238 中文编辑距离。相比之下,DeepSeek OCR 的 Gundam 模式使用少于 800 个标记(减少 97%)来实现几乎相同的结果。这种效率转化为更快的处理速度、更低的成本和处理更高文档量的能力。
DeepSeek OCR 中包含哪些 OCR 2.0 能力?
DeepSeek OCR 超越传统文本提取,具有先进的 OCR 2.0 功能用于全面的文档理解。该模型擅长图表解析,准确地从图形、柱状图和可视化中提取数据。它识别带有适当下标、上标和符号的复杂化学公式。几何图形理解解释图表、流程图和技术插图。Deep Parsing 功能分析完整的文档结构,在转换为 Markdown 时保留布局、表格、标题和格式。
在生产中运行 DeepSeek OCR 需要什么硬件?
DeepSeek OCR 针对各种硬件配置的高效部署进行了优化。对于生产使用,单个 NVIDIA A100-40G GPU 每天可以处理超过 20 万页,使其适用于企业级文档处理。该模型的架构在解码器中具有 5.7 亿激活参数,也允许它在性能较弱的 GPU 上运行,性能根据所选分辨率模式进行缩放。Tiny 模式(64 个标记)甚至可以在移动和边缘设备上运行。
如何在 HuggingFace 上使用 DeepSeek OCR?
在 HuggingFace 上使用 DeepSeek OCR 非常简单。首先安装 transformers 库,然后使用 AutoModel.from_pretrained('deepseek-ai/DeepSeek-OCR') 加载模型。我们提供了完整的 HuggingFace 部署指南,包括 Gradio 演示、推理 API 和模型优化技巧。您可以直接在 HuggingFace Spaces 上免费试用我们的在线演示,或下载模型到本地进行离线使用。
DeepSeek OCR 可以在 Ollama 中运行吗?
是的!虽然 DeepSeek OCR 主要通过 HuggingFace 分发,但您可以使用 Ollama 运行其他 DeepSeek 模型来处理文档。我们提供了详细的 Ollama 本地部署指南,包括 Docker 配置和 GPU 优化。对于完整的 OCR 功能,建议直接使用 DeepSeek-OCR 模型,该模型专门针对文档处理进行了优化,可以通过 Python API 轻松集成到 Ollama 工作流中。
DeepSeek OCR 如何处理 PDF 文档?
DeepSeek OCR 擅长处理 PDF 文档,可以将多页 PDF 转换为格式化的 Markdown,同时保留表格、标题和布局结构。我们的 PDF 处理教程提供了批量处理脚本、公式提取和图表识别的完整示例。相比传统 PDF OCR 工具,DeepSeek OCR 使用少 97% 的标记即可达到相同精度,大大降低了处理成本和时间。支持 JPG、PNG 和原生 PDF 输入。
DeepSeek OCR API 有速率限制吗?
DeepSeek OCR 是开源模型,您可以在自己的基础设施上运行,没有 API 速率限制。单个 A100-40G GPU 每天可处理 20 万+页面。如果使用 HuggingFace 推理 API,免费层有每小时请求限制,Pro 账户($9/月)提供 3 万次/月请求。对于企业级需求,我们建议本地部署以获得最佳性能和成本效益。完整的 API 集成指南包含自建 REST API 服务器的示例。
什么是上下文光学压缩(Contexts Optical Compression)技术?
上下文光学压缩是 DeepSeek OCR 的核心创新,通过 2D 视觉映射将文本压缩 10-20 倍,同时保持 97% 准确率。传统 OCR 逐字处理文本,而 DeepSeek OCR 将文档视为压缩的视觉表示,利用 DeepEncoder(SAM+CLIP+卷积压缩器)保留关键特征并消除冗余。这使得 AI 模型能够在更少的上下文窗口中处理更长的文档,突破了大型语言模型的上下文限制。详见我们的 ArXiv 论文解读。
DeepSeek OCR 与 Claude、GPT-4o 在文档处理上有什么区别?
DeepSeek OCR 是专门的 OCR 模型,在 OCRBench 上评分 834,超越 GPT-4o 的 736 分。关键区别:1) DeepSeek OCR 使用少 97% 的标记达到同等精度;2) MIT 许可允许商业使用和本地部署;3) 成本降低 97%;4) 专为 OCR 优化,支持化学公式、图表、多语言;5) 开源且可自托管。Claude 和 GPT-4o 是通用多模态模型,适合对话和推理,而 DeepSeek OCR 专注于高效文档提取。查看完整对比。
我可以将 DeepSeek OCR 集成到现有应用中吗?
完全可以!DeepSeek OCR 提供灵活的集成选项:1) Python SDK - 使用 transformers 库直接调用;2) REST API - 使用 FastAPI 构建自定义 API 服务;3) Docker 容器 - 一键部署到 Kubernetes 或云平台;4) HuggingFace 推理端点 - 无服务器调用;5) 批量处理脚本 - 用于大规模文档处理。我们的 API 集成指南包含所有主流编程语言的示例代码,支持异步处理、批量推理和错误处理。
DeepSeek OCR 的免费在线演示在哪里?
我们在多个平台提供免费的 DeepSeek OCR 在线演示:1) 官方 HuggingFace Space - 无需注册,直接上传文档体验;2) 本站演示页面 - 嵌入式交互界面;3) GitHub 仓库的 Colab 笔记本 - 可自定义参数。所有演示都支持实时处理,您可以上传图片或 PDF,选择不同的压缩模式(Tiny/Small/Base/Gundam),并立即看到提取结果。演示完全免费,无使用限制。
立即体验 DeepSeek OCR
试用在线演示,在 GitHub 上探索代码,或将革命性的文档理解集成到您的应用程序中。